This solution is evolving into a real-time GPU media platform: camera control, live capture, CUDA signal processing,
Direct3D rendering, audio analysis, neural audio compression, and groundwork for future image and video compression.
Generated: 2026-06-03 16:35:15 -06:00
What Has Been Built
Camera + Application Shell
Windows desktop camera control foundation
Camera service and desktop application projects for capture, configuration, and orchestration.
Shared data access projects for persistence and application state.
Installer project support for packaging the application.
CUDA FFT
Native CUDA signal processing
CUDA 13.1 native compute project for FFT, streamed GPU processing, and device memory operations.
cuFFT-backed audio frequency analysis with CPU and CUDA paths.
Native interop layer bridging managed .NET code to CUDA exports.
Direct3D Rendering
GPU-resident visualization
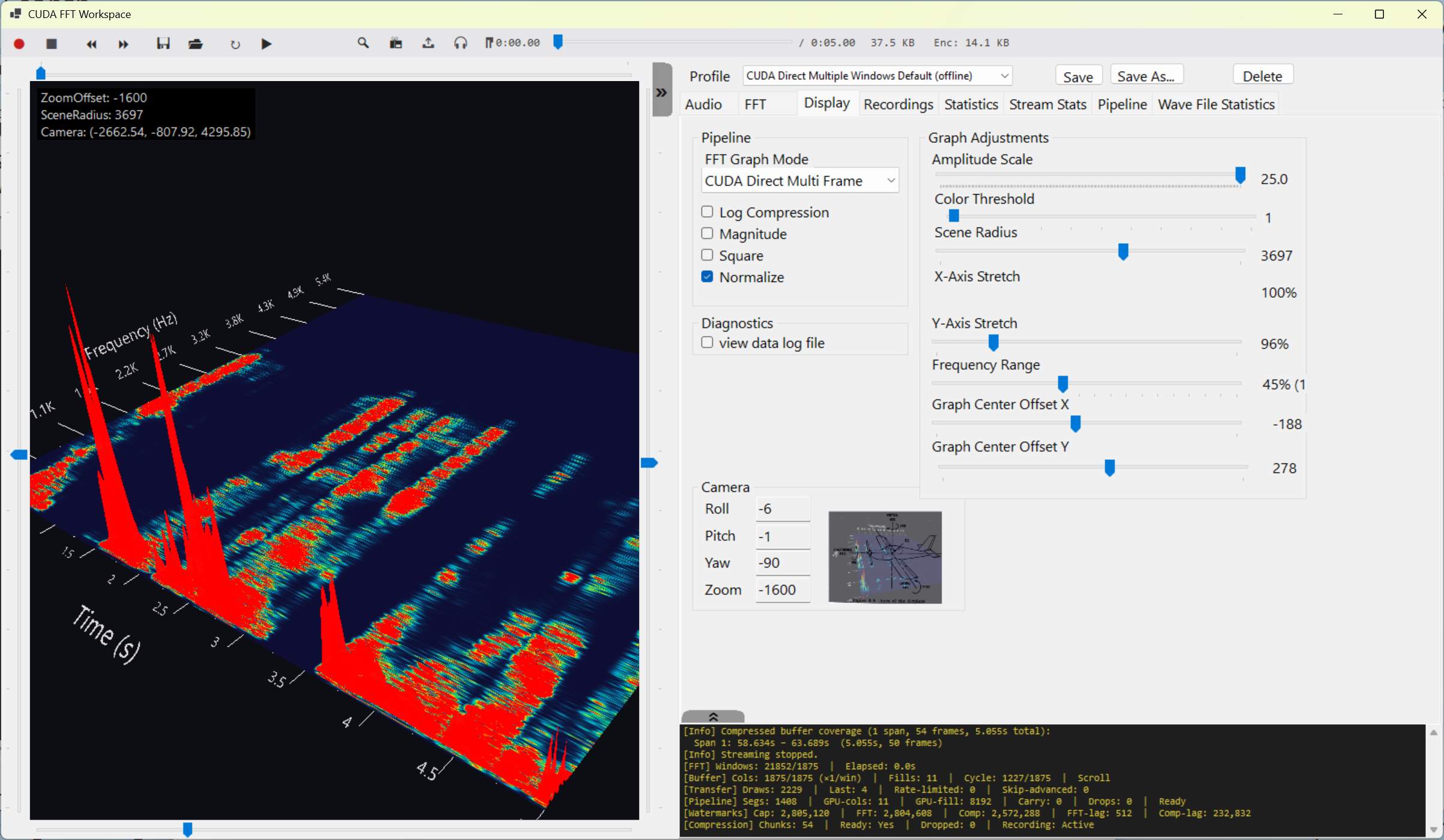
Vortice/Direct3D graphing for live FFT and spectrogram views.
CUDA and Direct3D interop for direct-draw rendering paths.
Multi-column render pipeline designed for 60 frames-per-second draw cadence.
CUDA FFT Workspace - GPU-resident visualization controls and live 3D FFT spectrogram.Audio Capture
Live audio capture and buffering
WASAPI capture path using configurable sample rate, channel mode, gain, and balance.
CPU ring buffer feeding the draw pipeline without blocking the audio capture thread.
Recording session support with progress tracking and compressed-buffer integration.
Real-Time Audio + FFT Pipeline
The current live pipeline separates audio capture, FFT rendering, and compression so that one subsystem does not stall the others.
1. Capture: WASAPI produces float audio samples and writes them into a ring buffer.
2. Draw cadence: a draw timer drains new samples at about 60 frames per second.
3. FFT preparation: the orchestrator preserves overlap, builds FFT windows, and submits batches to CUDA.
4. Rendering: Direct3D draws only when GPU FFT output is ready, preserving UI responsiveness.
5. Compression: the same captured samples are staged into 4096-sample DAC blocks and compressed independently.
DAC Neural Audio Compression
The solution now includes a libtorch-backed DAC integration path for GPU neural audio compression. DAC is used as a compact audio codec:
PCM samples are encoded into residual-vector-quantized codebook indices, then decoded back to PCM when needed.
DAC Neural Audio Compression - GPU media workstation with DAC CUDA, cuFFT, and camera job scheduling.
Runtime
libtorch C++
libtorch is linked into the native CUDA compute project.
Runtime DLLs are copied next to the application output for Debug and Release x64 builds.
The same runtime is intended to support future image and video compression work.
Models
TorchScript DAC modules
Encoder CNN: audio to latent representation.
Quantizer encode: latent representation to codebook indices.
Quantizer decode: codebook indices back to latent representation.
Decoder CNN: latent representation back to audio.
Interop
Managed to native bridge
C# builds compression descriptors and calls the CUDA interop API.
The native CUDA layer loads DAC models lazily on first use.
Device pointers are passed through without unnecessary host round trips when possible.
Non-Blocking Compression Design
Compression is intentionally decoupled from the draw path. The draw loop does not wait for DAC compression to finish.
CPU staging path
Fire-and-forget blocks
Incoming audio is copied into 4096-sample staging blocks.
Completed blocks are dispatched on ThreadPool work items.
A semaphore serializes compression work because the codec instance owns stateful device pointers.
Stop/dispose drains queued work so recordings can finalize safely.
GPU pipeline path
Event-polled device pipeline
GPU audio pipeline exposes separate write, FFT-read, and encode-read heads.
Encoding can be submitted when enough device-resident samples are available.
State snapshots report pending code frames and ring-buffer free space.
State Available from the Active GPU Audio Pipeline
The active GPU audio module can expose runtime status without blocking the render loop. The managed state snapshot currently includes:
WriteHeadDevice-ring write position
FftReadHeadFFT consumer read position
EncodeReadHeadDAC encode consumer read position
FftAvailableSamplesSamples ready for FFT
EncodeAvailableSamplesSamples ready for DAC encode
FreeSpaceSamplesRemaining device ring capacity
EncodeDoneLast encode event status
DecodeDoneLast decode event status
CodesPendingFramesEncoded frames waiting in code buffer
GPU Media Tooling in the Solution
CUDA_Compute_cuFFT
Native GPU compute engine
Hosts CUDA FFT, Direct3D interop, audio compression exports, GPU buffer operations, and libtorch DAC model loading.
MindSight_Interop_cuFFT
Native interop pass-through
Loads the CUDA compute DLL and exposes stable native entry points to the managed application layer.
Signal_Relay
Managed GPU orchestration
Coordinates security-camera capture, relay routing, FFT submissions, draw timing, compression dispatch, and GPU media state reporting.
Signal_Relay - security camera signal routing with compression-management coordination.
For camera monitoring workloads, Signal_Relay acts as the managed control point between live feeds and compression management: it can stage captured signal blocks, keep relay activity responsive, and hand audio or future video/image payloads to compression paths without blocking camera review.
Vortice_FFT3D_Graph
Direct3D visualization
Provides real-time GPU-rendered views for FFT surfaces, spectrogram columns, labels, scene controls, and visual tuning.
Contains native codec contracts and host-side CUDA codec experiments used to evolve compressed-audio GPU workflows.
Why This Matters
The application is being shaped as a GPU-first media workstation. Audio and visual analysis stay close to the GPU, reducing unnecessary
transfers and leaving room for camera, audio, image, and video intelligence features to share the same acceleration stack.
Current focus: completing DAC runtime verification, surfacing compressed/uncompressed byte counts, and using the libtorch runtime as the shared foundation for future image and video compression modules.